# Workflow management
After data source and data model configuration, the next step is data processing, including data cleaning, data extraction, data export and other routine operations, as well as label calculation, One ID, etc.
# Add Workflow
Go to Data Integration > Workflow Management, create a folder (optional), add a workflow under the folder and configure the workflow as needed.
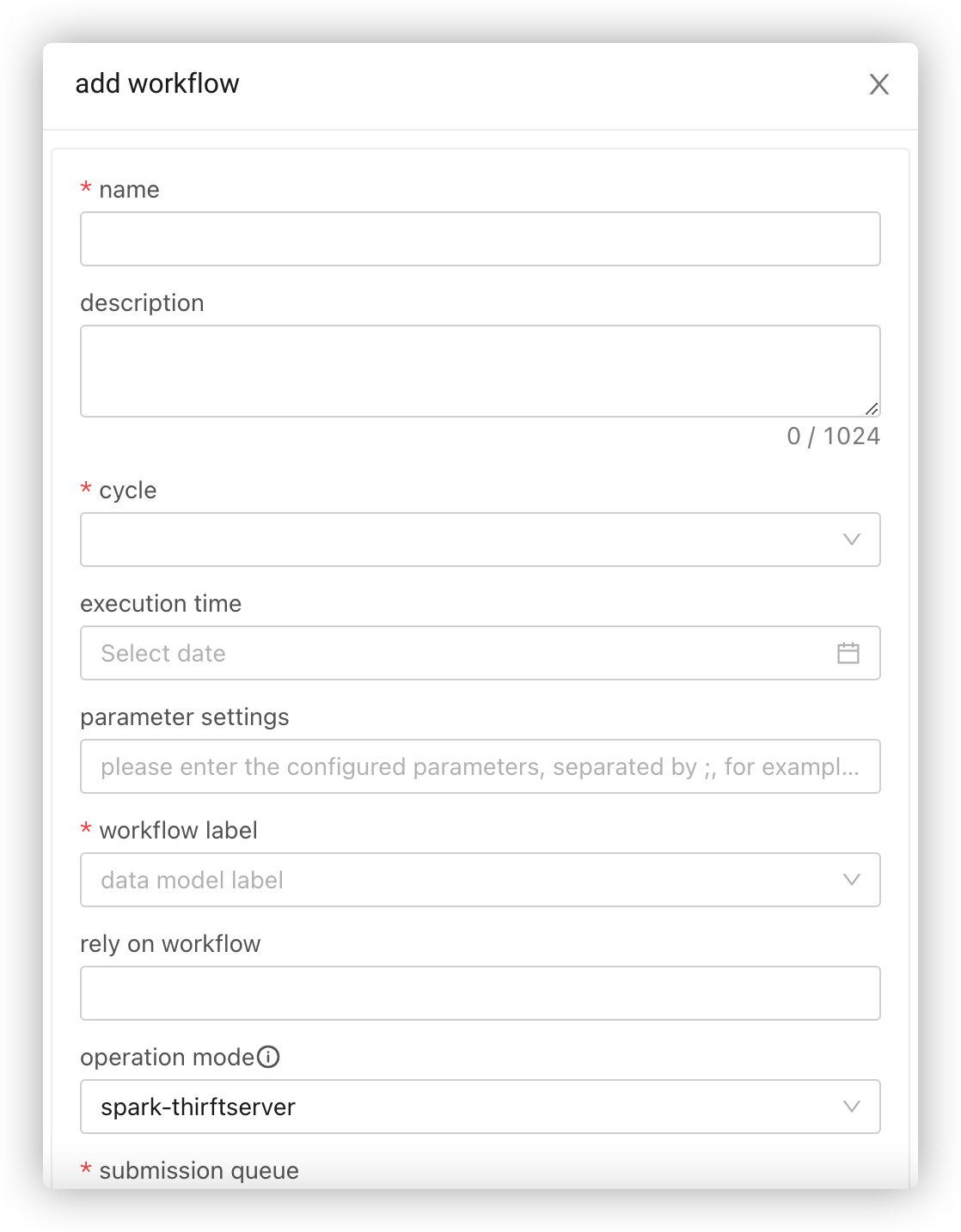
Cycle: Select single task, periodic task or real-time task, while the former two are for offline task calculation.
- Single Task: Run the task once.
- Periodic Task: Run the task at regular intervals.
- Real-time Task: Keep the task running.
Parameter Settings: Global parameters required by the workflow.
Assuming that the time parameter is set as pt=${yyyy-MM-dd-1}, you can fill in ${pt} in the downstream node to reference the parameter and the platform will replace the variable with a specific date.
Rely on Workflow: If the current workflow needs to be executed after another one, then this item is required.
Submission Queue: To achieve more refined workflow allocation and management. For details, see Queue Management.
Task Priority: Set the workflow priority.
Owned Directory: The folder where the current workflow is located.
# Data Integration
Integrate data from the data source into the system.
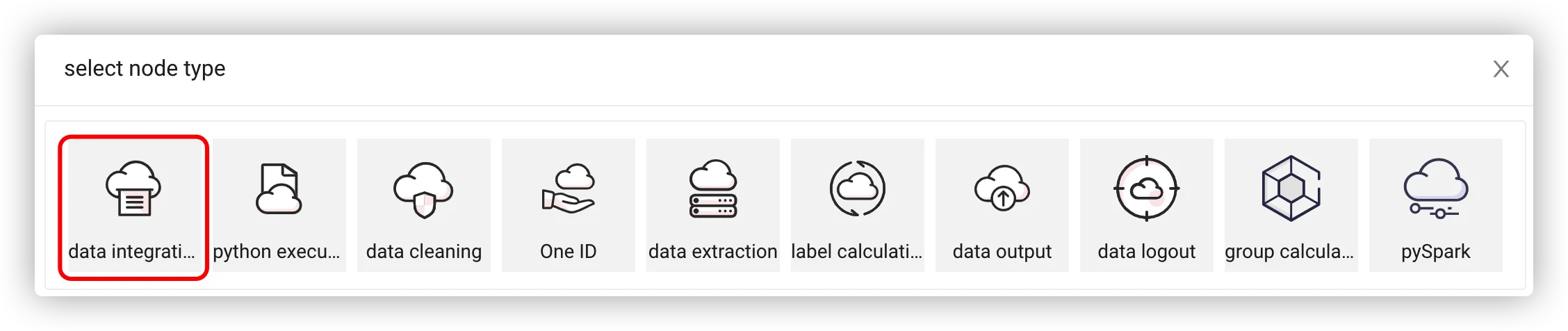
# Add Integration Node
Select the data integration node.
# Edit Integration Node
Select the data source and data model to be read.
Click + to create a name of the Cassandra model.
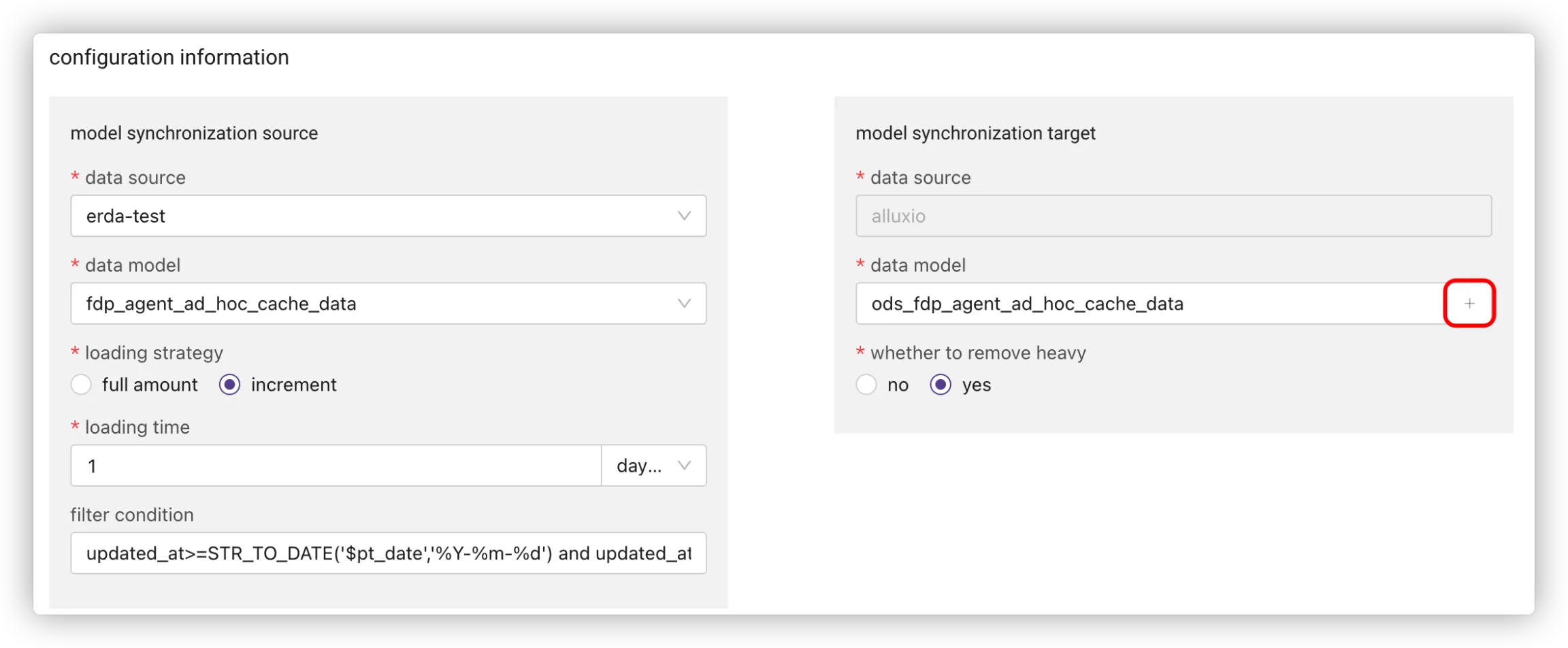
- Select fields and click > to add to Cassandra model.
Click Edit to modify the model fields, including the primary key and partition key. The primary key must be included in the model.
Click Add to to add fields and set default values for them.
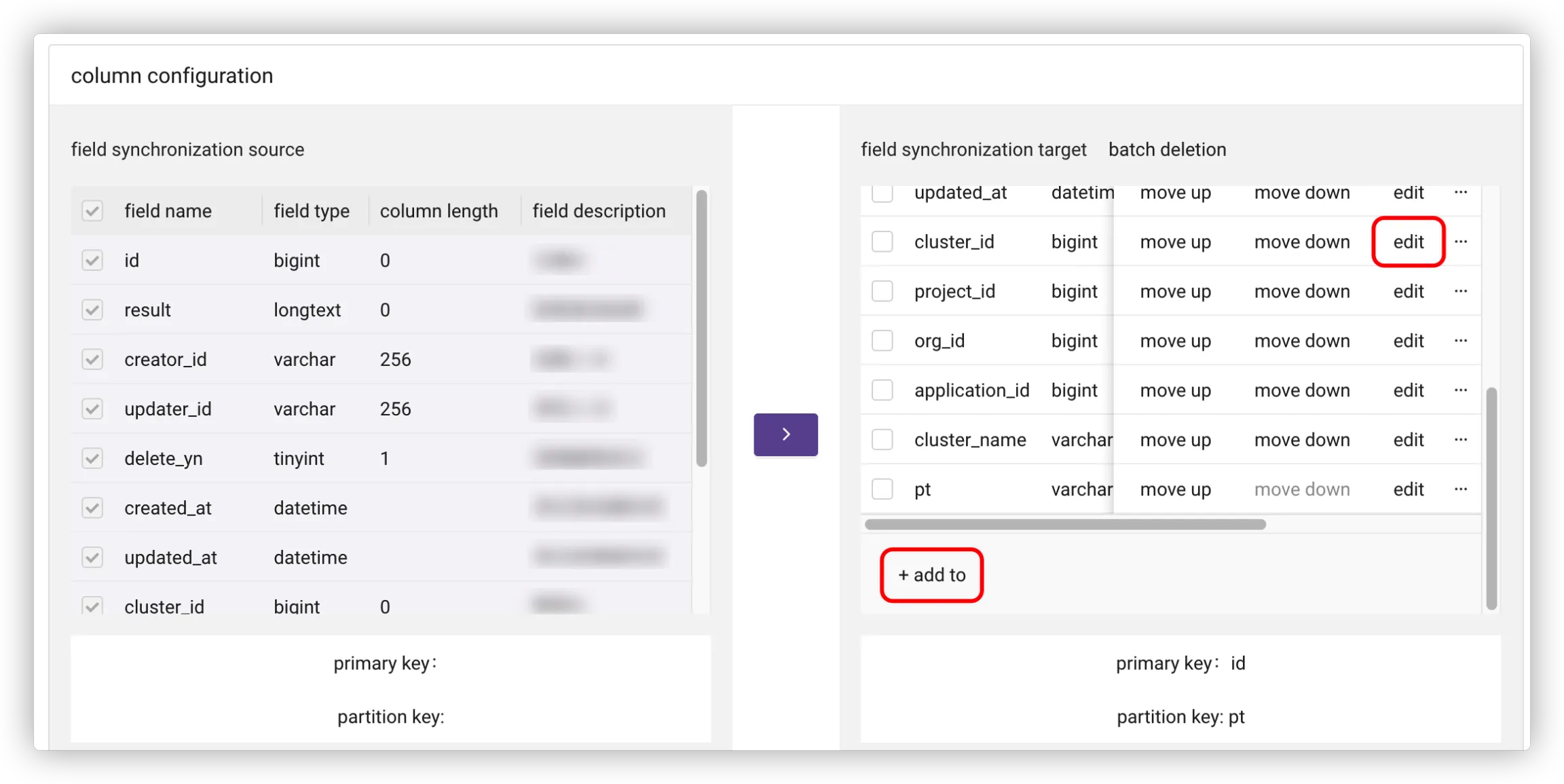
You can add quality rules when editing model fields or adding fields.
Click Sure to save the configuration.
# Data Cleaning
# Add Cleaning Node
Select the data cleaning node.

# Edit Cleaning Node
- Set the cleaning table name.
- Select the internal table of the system to be cleaned as the main model, and add filter conditions to filter the fields in the table, which is equivalent to the where statement in SQL.
- (Optional) Add a related model.
- Select the fields in the model, and click the arrow icon to synchronize to the cleaning table.
- Edit or add new fields as needed (the model on the right must contain a partition key).
# Data Extraction
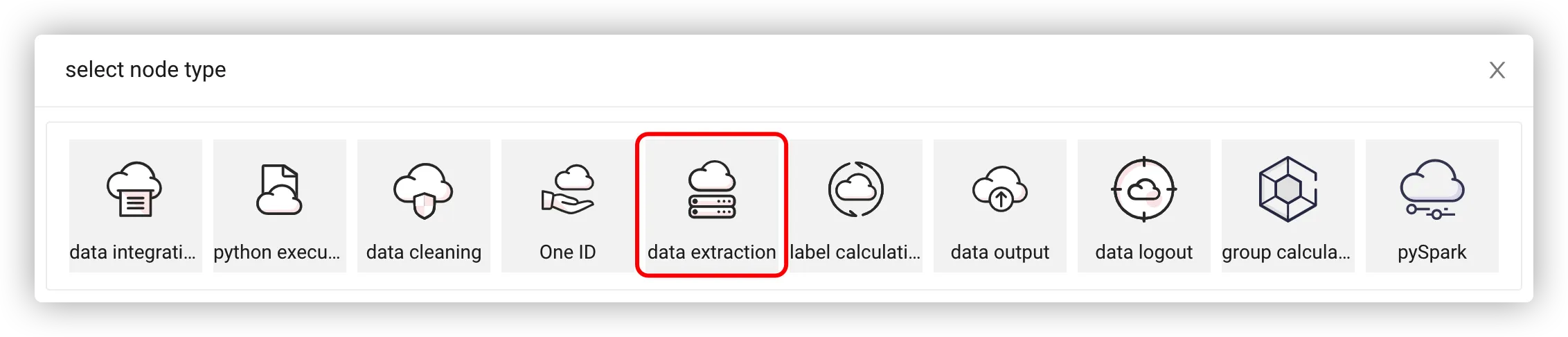
# Add Extraction Node
Select the data extraction node.
# Edit Extraction Node
- Set the extraction table name.
- Select the internal table of the system to be extracted as the main model, and add filter conditions to filter the fields in the table, which is equivalent to the where statement in SQL.
- (Optional) Add a related model.
- Select the fields in the model, and click the arrow icon to synchronize to the extraction table.
- Edit or add new fields as needed.

# Data Output
Export the processed data within the system to an external data source.
# Add Output Node

# Edit Output Node
- Select the data model to be exported.
- Select the data source (EXTERNAL).
- Select the data model under the data source (create it in advance, and the exported field names, quantity, and order must be the same).

# One ID
One ID is a unique ID generated by encrypting each piece of data in the selected field.
- You can get the One ID for the configured fields according to the priority, and then compare the same One ID data to check the differences and find the same user in different systems.
- The data generated by the One ID node in the workflow will be stored in the dim_cust_oneid latitude table of the data lake, and the newly generated One ID data will replace the old one and then the latest data will be reloaded.
- The data table dim_cust_oneid generated by One ID has 6 fields (one_id, phone, app_id, open_id, member_id, email). If the selected field comes from these fields, then it will be displayed as null.
- One ID will be generated according to the phone, member_id, email, app_id and open_id fields in turn. If you set the first priority as null, then generation rules will be followed in order according to the priority.
For example, if you have set phone, member_id, and email fields, the One ID will be generated by encrypting the phone field. If the phone field is null, the One ID will be generated by encrypting member_id field, and so on.
One ID is designed to solve the problem of being unable to find the same user in multiple systems or multiple data sources. Using this feature reasonably, you can find the same users in different data sources by key fields and compare information similarities and differences.

Create a workflow and create the required node.
Based on the created node, select the One ID node.
Create a new data model (usually two, that is, repeat the following steps twice):
3.1 Click New Data Model.
3.2 Select a data model.
3.3 Complete the business description of the fields in the data model.
3.4 Click OK to save the configuration.
Run the workflow.
The results of One ID can be queried in Data Integration > Ad Hoc Query.
Find the dim_cust_oneid latitude table.
Copy the corresponding query SQL (or write by yourself).
Execute the SQL and get the result.
# Label Calculation
You can configure labels for the fields in the table, and the data platform will synchronize the source data to the member platform, based on which the member platform can add rules for the fields and synchronize them to the data platform, then the data platform can make calculations according to the field rules. If no rules are configured on the member platform, the node will not calculate in the actual execution.
For example, there are age fields in data of one million. You can set the age field as an indicator in the label calculation node, set rules on the membership platform (age greater than 18 is adult and younger than 18 is minor), and then the data platform can tell who is an adult or a minor by calculation.
# Add Label Node
Select the label calculation node.

# Edit Label Node
- Click Add Indicator.
- Select the table name and field.
- Click OK to save the configuration.

# Data Logout
If you do not want the system to retain data, you can clear the data left in the system through data logout.

# Python Execution
You can perform machine learning with Python and view the running results through logs.

# Group Calculation
On the basis of label calculation, you can divide groups of people through group calculation.

# Workflow Details
Go to Data Integration > Workflow Management to view the workflow details.

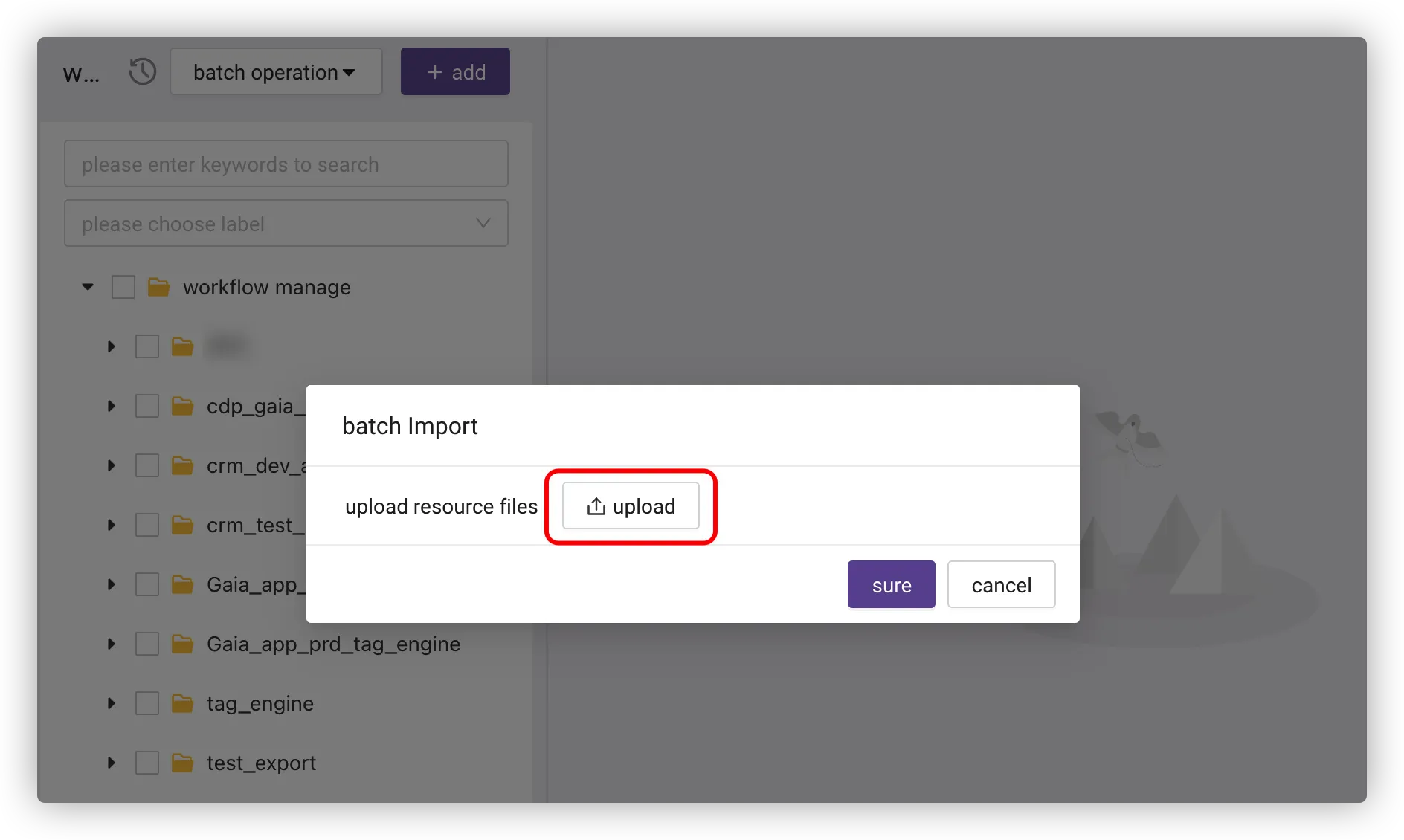
# Workflow Import and Export
To export workflows, select the workflow folder or workflows and click Batch Export.
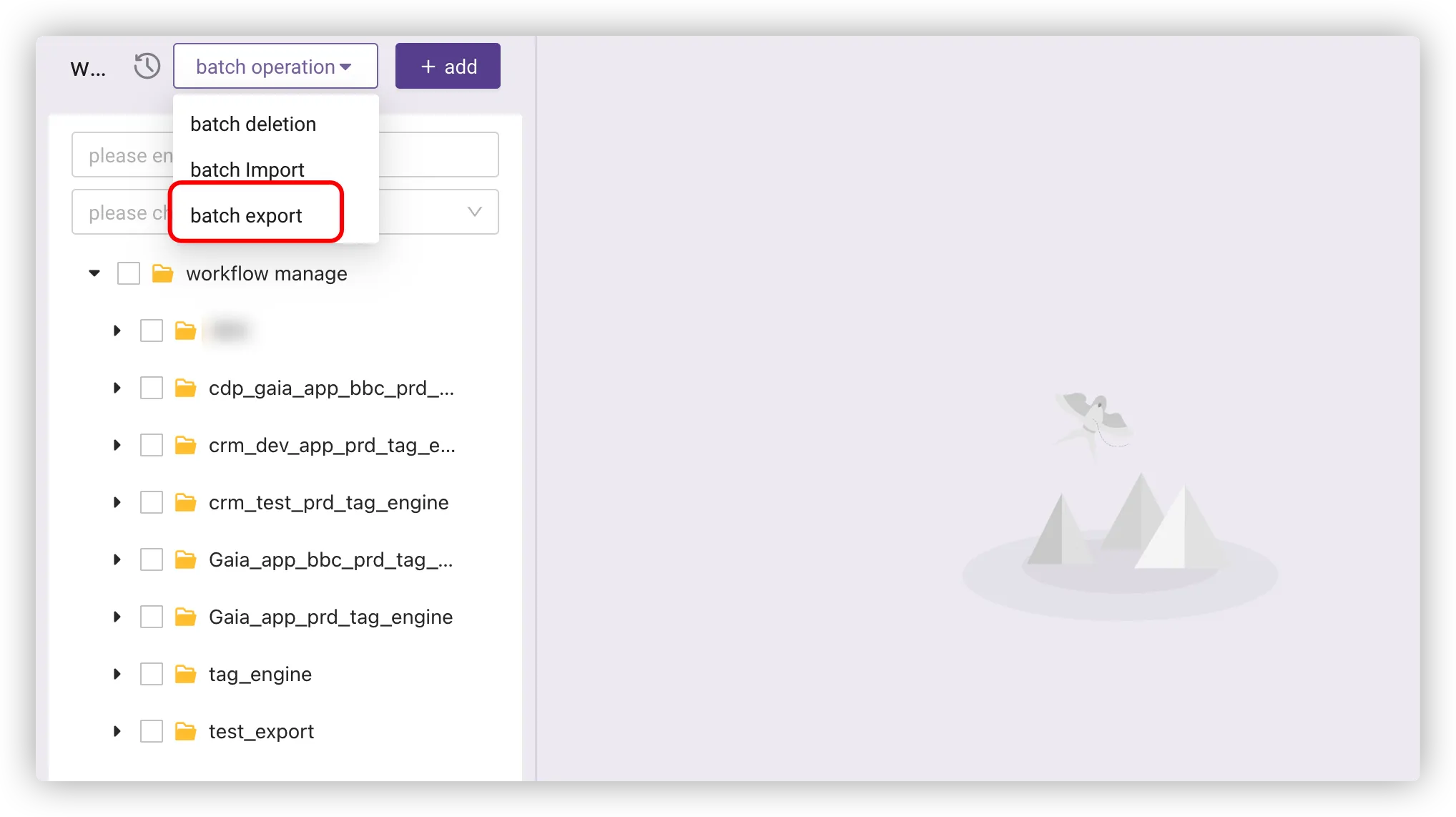
To import workflows, click Batch Import > Upload, and select a local file with a suffix of .workflow.