# 使用持续分析排查 JAVA 应用 CPU 高的问题
# 背景说明
我们在一个 java 应用中构造了一个接口,调用该接口后会触发一个持续消耗 CPU 的方法,进而导致该应用的整体响应时间偏高,该文章用于说明如何使用 Erda 来最终定位到是哪个方法消耗的CPU 。
# 使用 Erda 定位问题
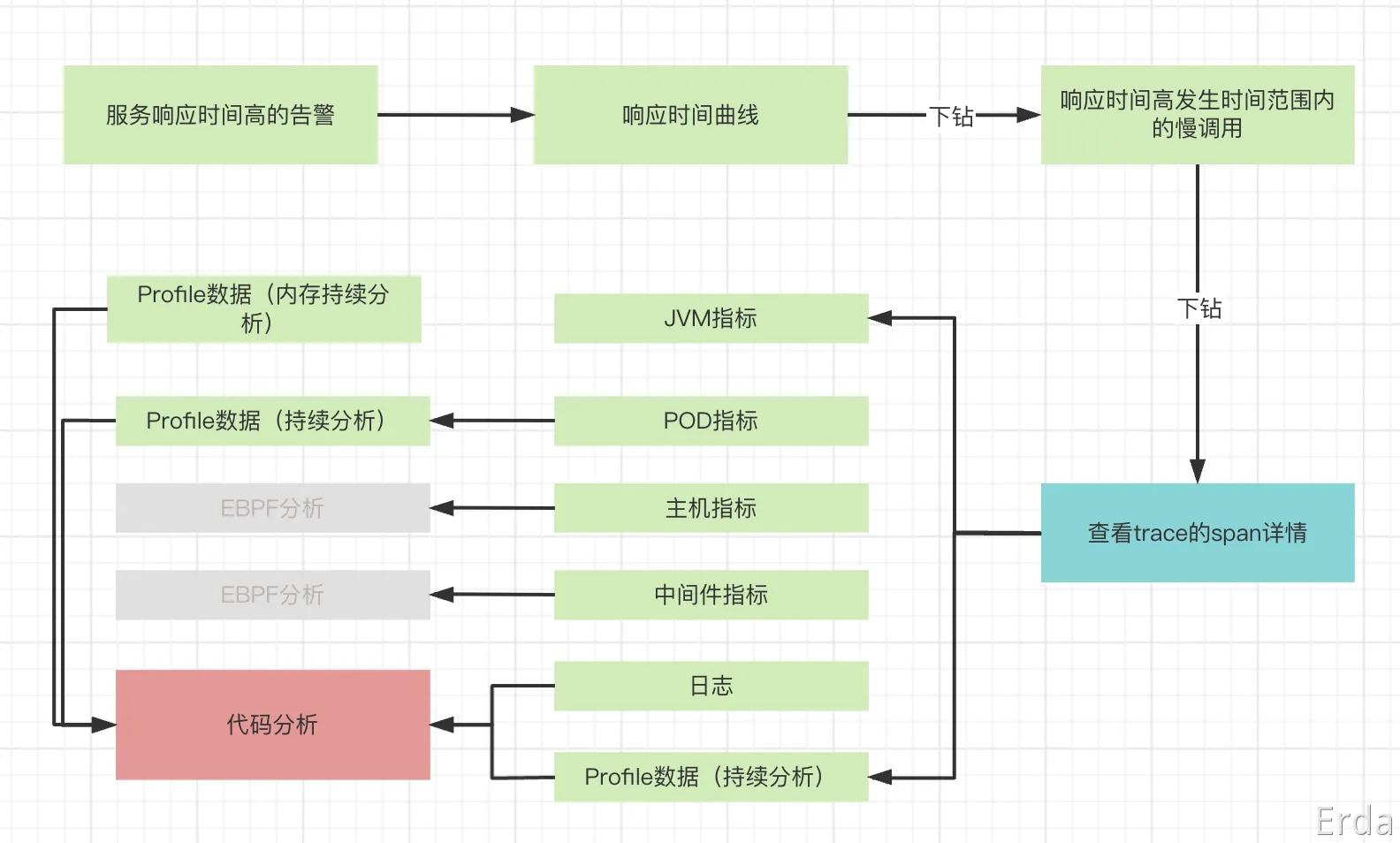
CPU高,最直接的影响就是导致服务的 RT 升高,如果配置了告警,用户会收到一条服务响应时间高的告警,同时可以在微服务治理平台中的服务总览页面中看到响应时间曲线显著升高。


导致服务响应时间高的因素有很多,我们可以从响应时间图表下钻到 trace,找到慢调用的 trace,去查看是哪个环节导致响应时间慢,Erda 将 span 发生时间对应的容器指标,主机指标,中间件指标,profile 等做了关联,我们可以在 span 的上滑页面中查看这些指标。可以看到容器的 CPU 使用率对应的时间也同步涨了起来。

最后我们可以使用持续分析功能来定位具体是哪个方法导致的 CPU 使用率高,进入到微服务治理平台中,去搜索对应的应用服务,查看 itimer 类型的 profile 数据,可以比较清楚得看到最占用 CPU 的方法是 .[vdso],再往下有一个服务代码中的 cpuoverload 方法。
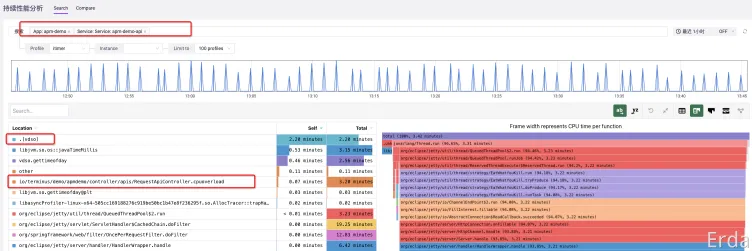
切换到火焰图格式,可以比较清楚的看到方法之间的调用关系,cpuoverload方法调用的底层的 .[vdso],从而消耗了大量的 CPU。

最后我们贴一下最终有问题的 cpuoverload方法实现。可以看到方法中调用有大量的 System.currentTimeMillis()调用,而 System.currentTimeMillis()的实现是通过 vdso.gettimeofday 来实现,可见在持续分析这里不仅可以捕获到用户态的代码调用,甚至也能捕获到系统级别的代码调用。
public String cpuoverload() {
// 角度的分割
final double SPLIT = 0.01;
//
// 2PI分割的次数,也就是2/0.01个,正好是一周
final int COUNT = (int) (2 / SPLIT);
final double PI = Math.PI;
// 时间间隔
final int INTERVAL = 200;
long[] busySpan = new long[COUNT];
long[] idleSpan = new long[COUNT];
int half = INTERVAL / 2;
double radian = 0.0;
for (int i = 0; i < COUNT; i++) {
busySpan[i] = (long) (half + (Math.sin(PI * radian) * half));
idleSpan[i] = INTERVAL - busySpan[i];
radian += SPLIT;
}
long startTime = 0;
int j = 0;
while (true) {
j = j % COUNT;
startTime = System.currentTimeMillis();
while (System.currentTimeMillis() - startTime < busySpan[j])
;
try {
//这里的if控制可以注解掉,让Thread.sleep(idleSpan[j])一直执行。
if(idleSpan[j]<70){
Thread.sleep(idleSpan[j]);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
j++;
}
# 总结
最后,我们可以总结出排查JAVA服务响应时间高的一般套路,可以借助 Erda 的微服务治理平台,总服务的黄金指标(R.E.D)一路往下分析,ERDA提供了时间维度的指标跟 trace 的关联,以及 trace 中 span 发生时间点上的 pod 执行,机器指标,中间件指标,jvm 指标,日志的关联,最后也提供了代码级别的 profile 数据用于将问题原因锁定到具体的代码实现。