# 自定义大盘
在可配置大盘还没诞生时,每个需要展示数据的页面都需要定制化开发,但需求经常会变化,但这样就带来了沟通的成本与时间的损耗,显而易见这样的方式并不灵活,想要随时定制图表的话就无法满足了。
在此之前创建可视化图表/大盘的时候,可能会有以下几个问题:
- 需求总是有偏差,反复改动且不尽人意。
- 展示在不同设备之间无法做到统一,视觉效果不一致。
- 可视化效果耗时耗力,毫无扩展性。
- 无法应对频繁的需求变化。
大盘系统就是用来解决这一问题,前端和后端的底层实现都能够统一用一种方式来实现,并且能够提供给用户自定义图表页面的功能。
使用大盘后,您的收益:
- 统一平台上的所有图表,达到UI风格一致,提升美观度。
- 展示自定义的指标数据和日志指标数据。
- 操作简单,低代码式操作,敏捷获取数据分析。
- 解决沟通准确性与时间成本问题,拥有了自身的选择权。
- 复杂查询亦可通过表达式解决,无需定制。
提示
具备 SQL 基础可帮助您快速上手。
# 操作
运维大盘是大盘系统的一部分,也称为自定义大盘,可以为运维人员与开发人员快速搭配出大盘以监控各种资源的实时情况以供排查分析使用。
# 进入自定义大盘
进入 微服务治理平台 > 诊断分析 > 自定义大盘。

# 编辑自定义大盘
点击 新建自定义大盘,进入编辑模式,点击右上 + 号,选择 图表类型 为柱状图。
# 编辑图表
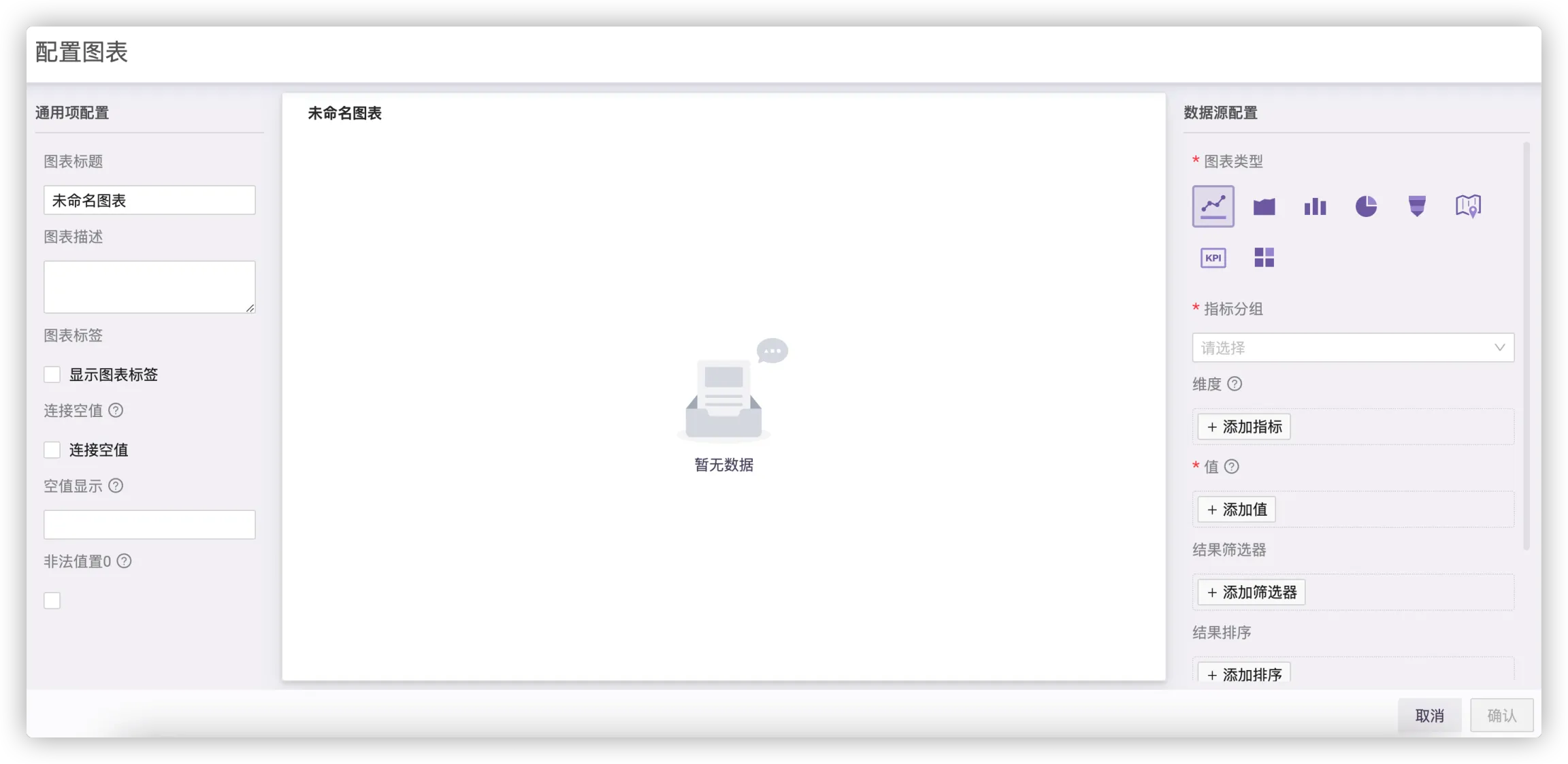
左侧通用项目可以输入图表的名称、简介等。
# 配置数据源
# 指标分组(FROM)
指标的数据源,也就是指标的类别,分为多级指标,一级指标是指标类别概览,二级指标是对一级指标的二次处理或细分,如慢HTTP请求。 选择HTTP请求-所有HTTP请求。

# 维度(GROUP BY)
依据选定条件或者字段分组,选择1小时为间隔代表聚合每个小时的数据,便于分析,也可选择时间格式,即时间栏和数据详情的时间格式选择添加指标-时间,点击添加好的标签下的时间配置进入,如图所示:
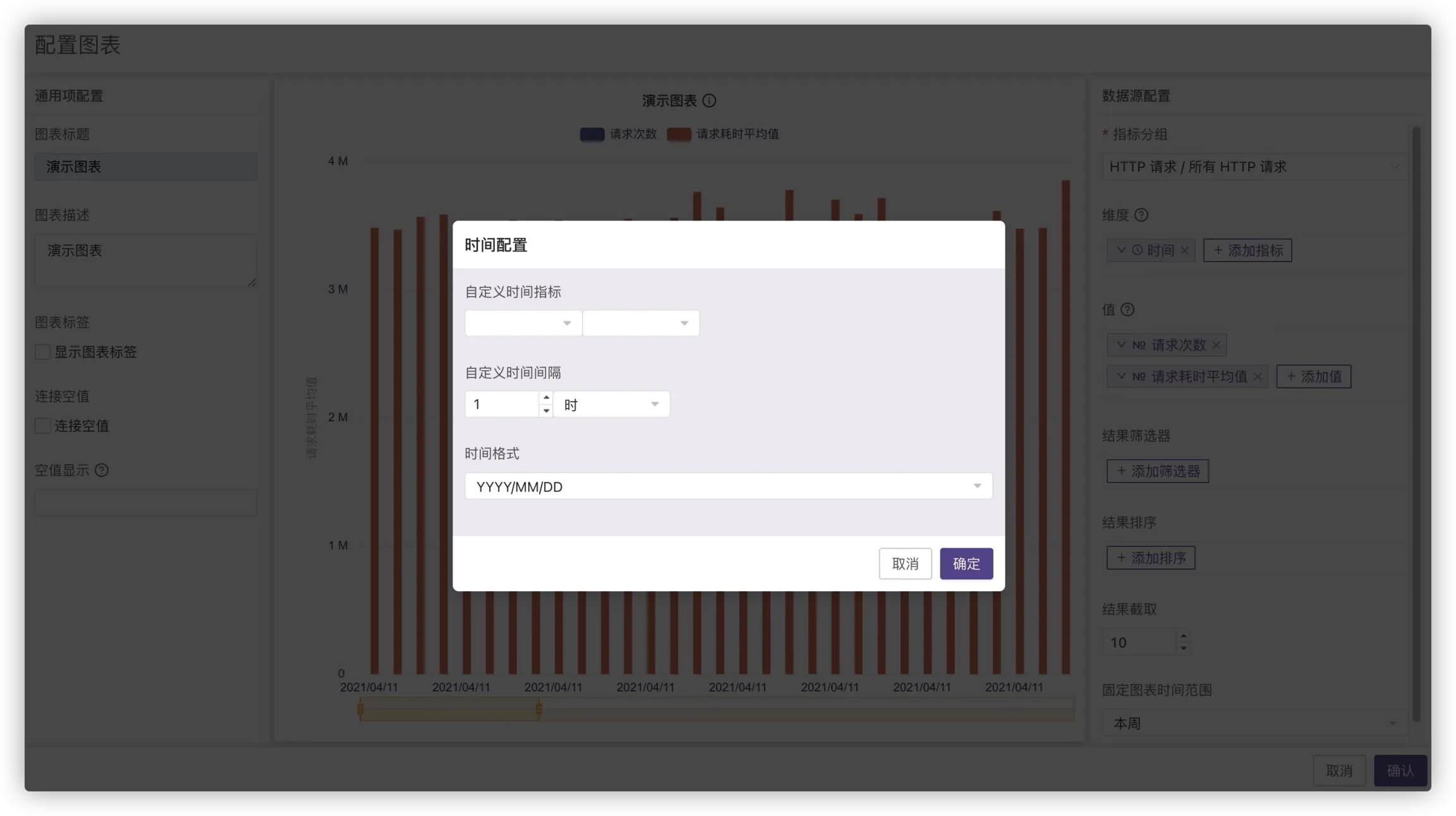
点击添加好的标签,选择字段配置,可设定自定义别名

# 值(SELECT)
指标下的数据,也就是字段,可多选,添加请求次数与请求耗时平均值。添加后点击生成的标签,可对字段进行聚合操作,或设置别名。具体请参见 应用指标 。
提示
如果您不确定多个值是否为一种单位,建议一个图表一个值,单位不一致可能会导致图表无法正常显示。

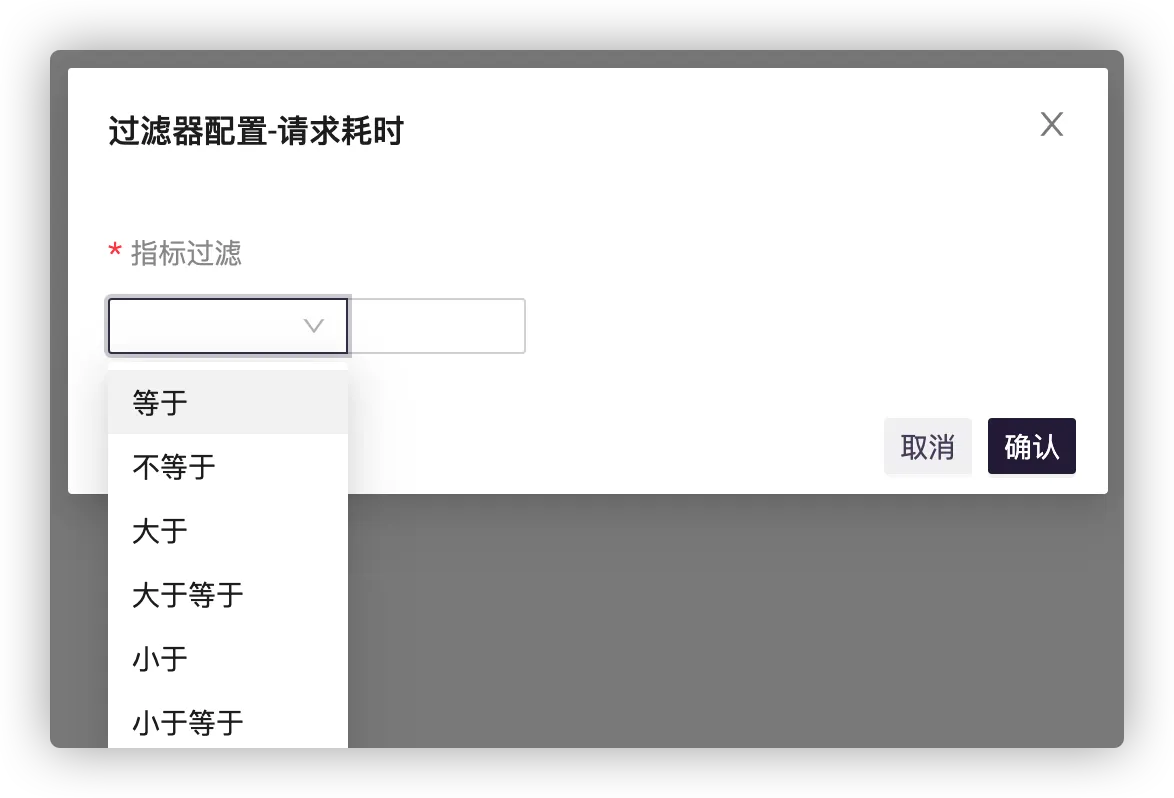
# 结果筛选器(WHERE)
可对字段进行条件过滤,包含常用的比较运算符,也可选择自定义函数表达式。
# 结果排序(ORDER BY)
对查询的字段进行排序,如果查询的字段为聚合方式,那排序的字段也要选择对应的聚合方式。

# 结果截取(LIMIT)
截取查询结果的数据条数,如果查询带有排序则按排序顺序截取,若不填则显示所有查询结果。
# 固定图表时间范围
限定数据产生的时间范围,不受全局时间范围自定义配置影响。
如需自定义时间范围,可不填,由大盘全局时间范围控制,也就是如下全局时间范围自定义配置。
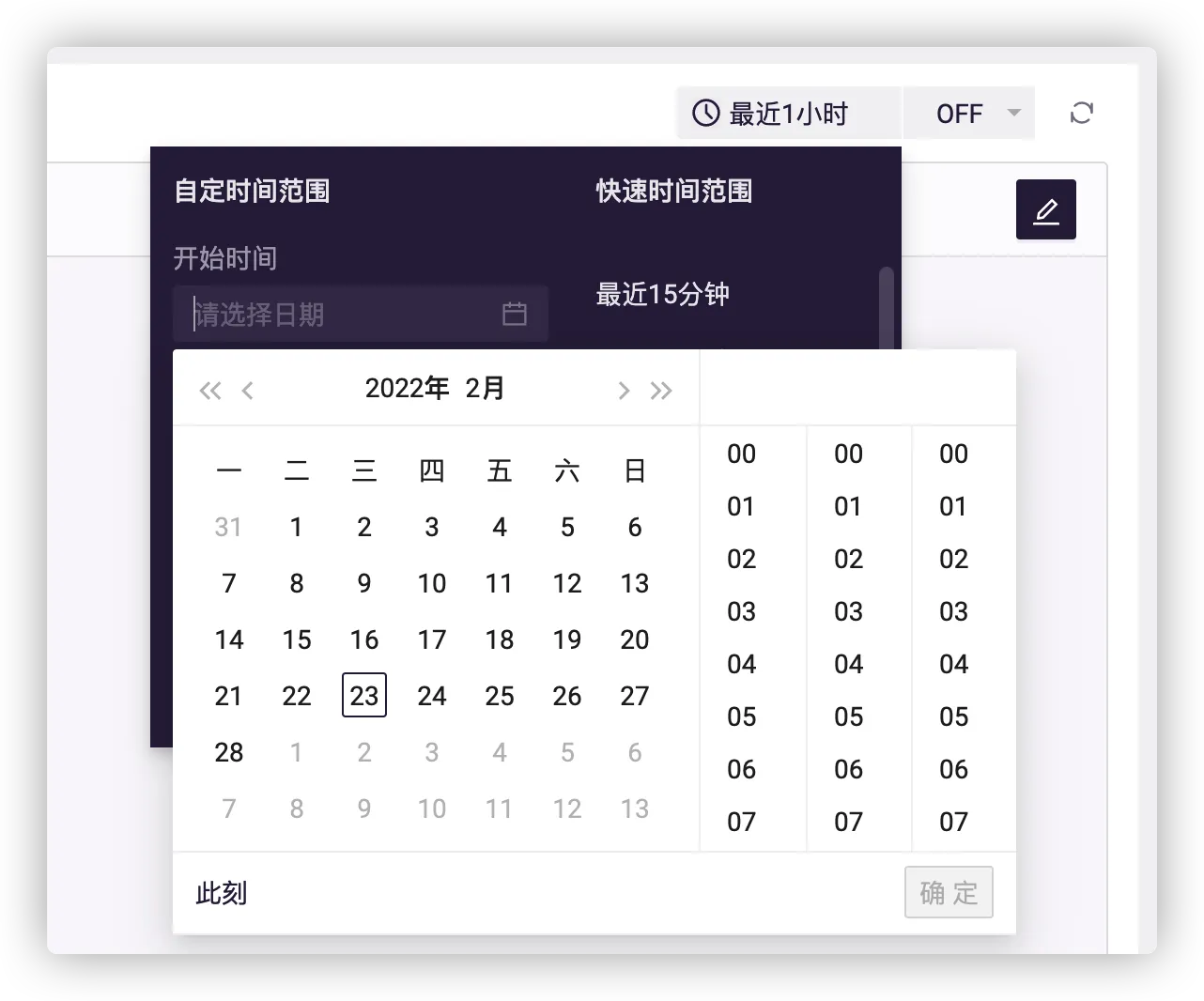
# 保存与调整
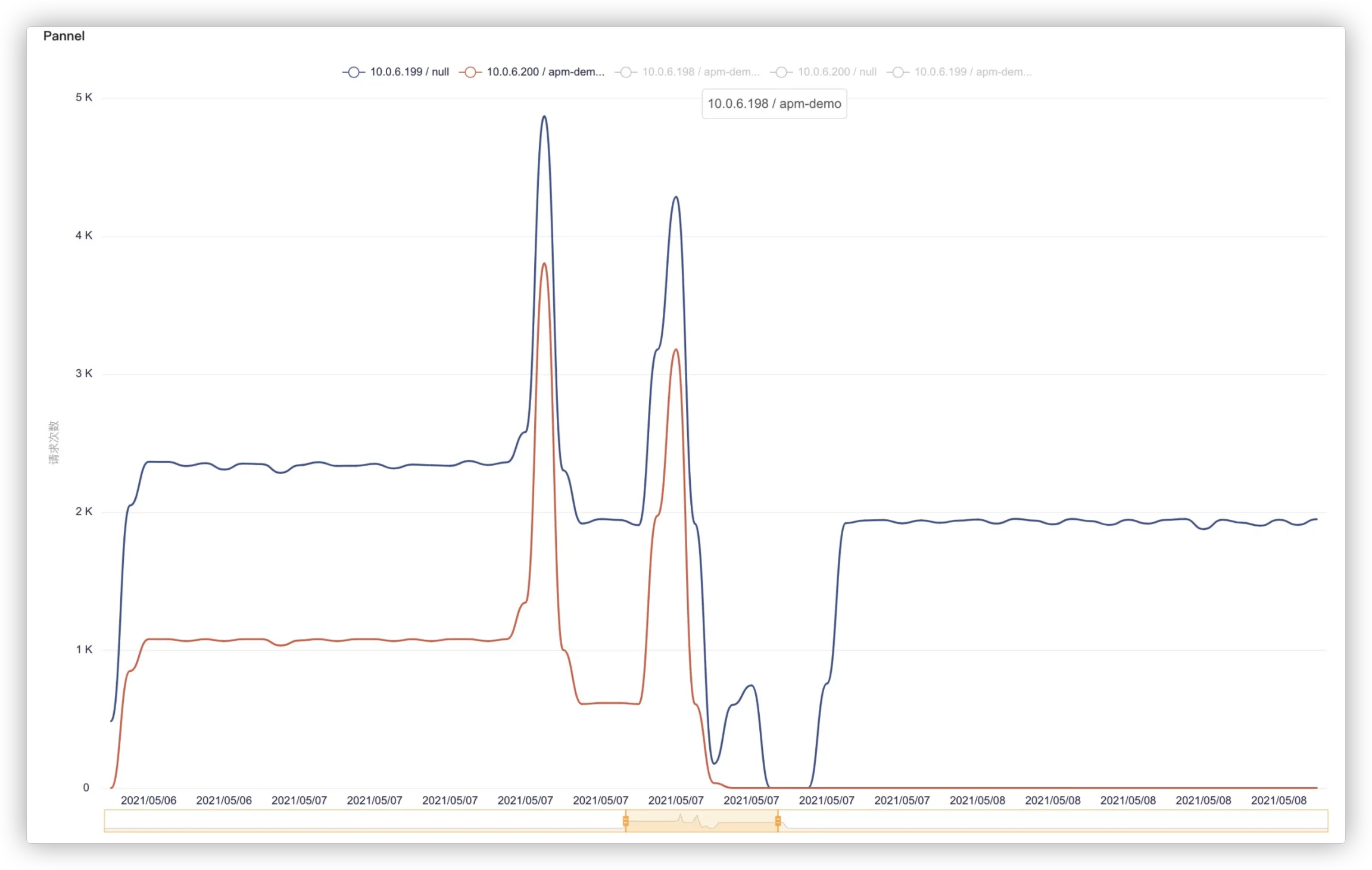
右下角确认保存返回大盘编辑器,查看大盘预览,鼠标悬浮到柱状图上,可以显示详细信息:
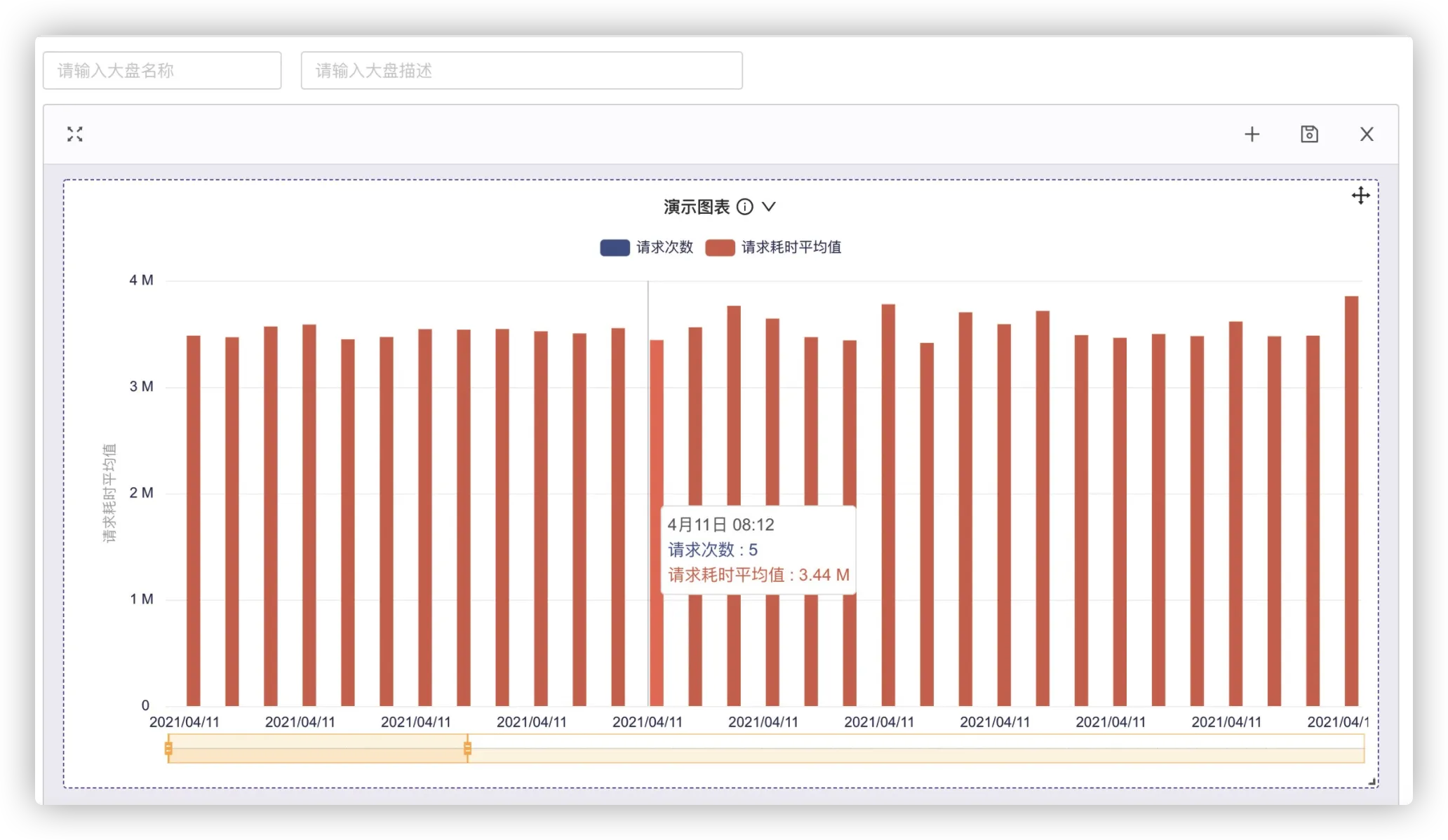
点击标题可查看更多图表操作,点击导出图片即可生成报表图片以便分享与沟通,亦可全屏查看实现盯盘效果。
如需调整图表大小与形状,还可选取右上角拖拽与拉伸图表。

输入大盘名称和描述后,点击保存,即可保存,随时查看。
# 查看面板
系统提供了一些内置面板,如服务分析-事务分析下的图表。
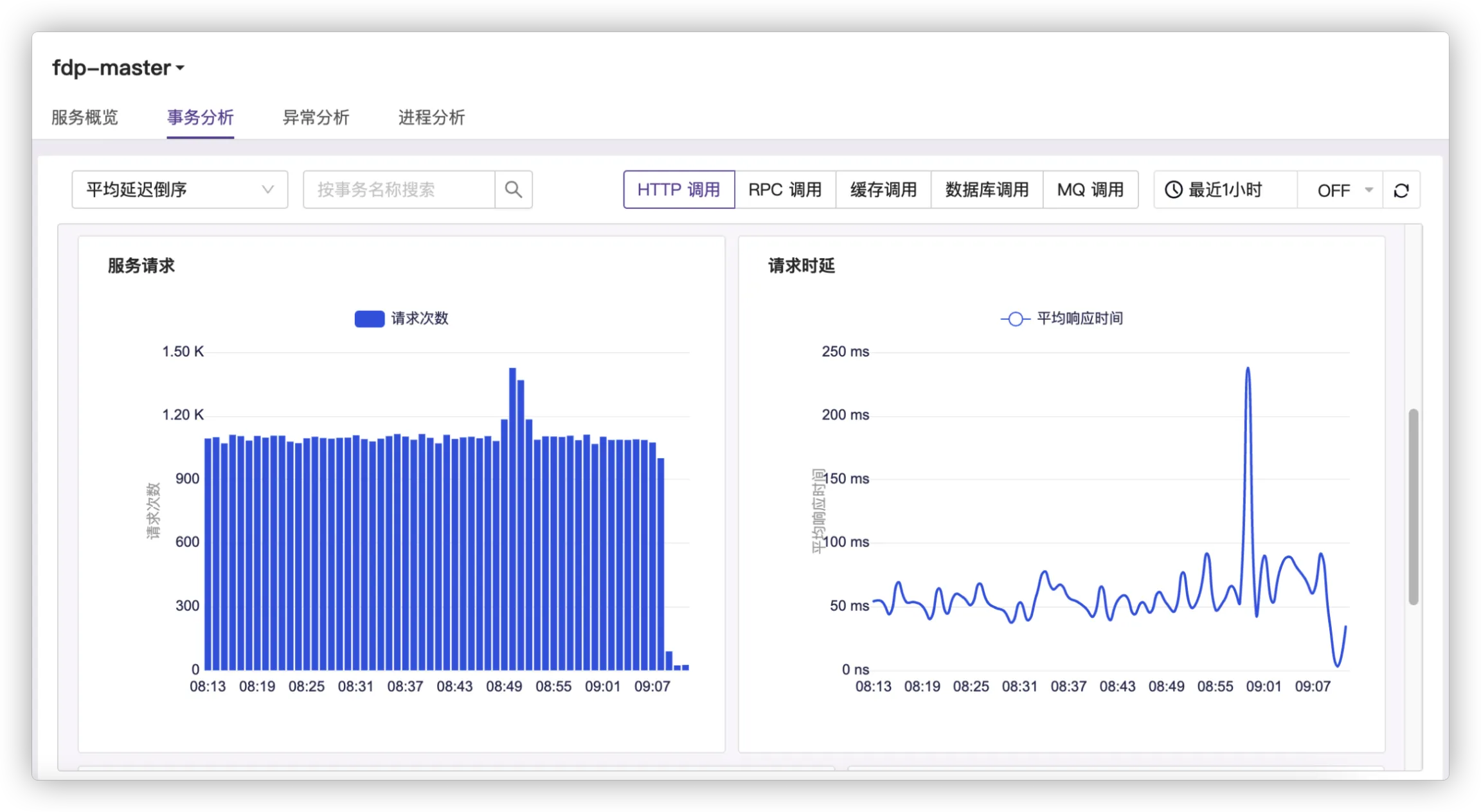
其使用方法也是类似的,若想对某一图表操作,只需点开图表右上方。
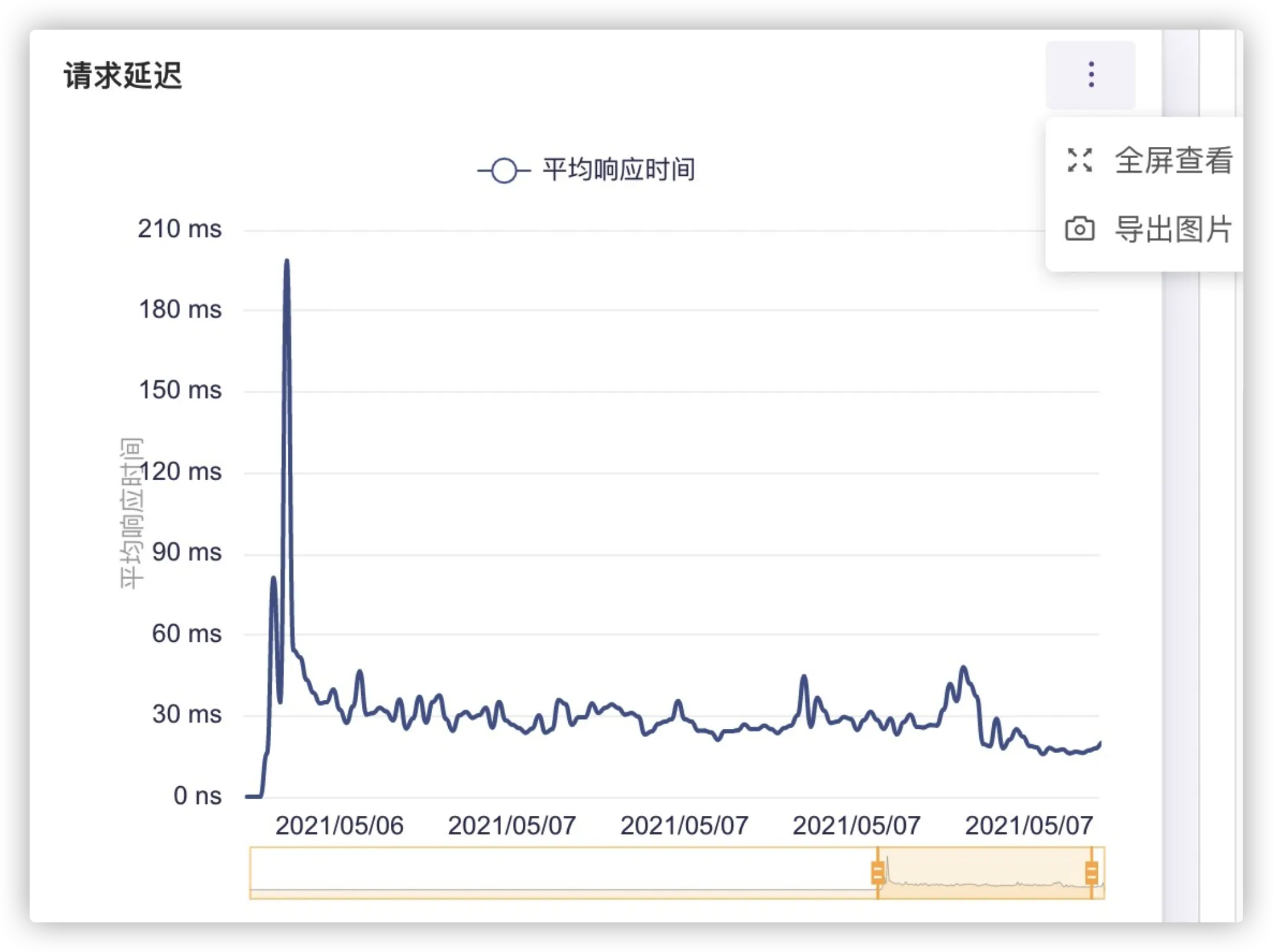
全屏查看:使当前图表铺满可显示区域,可在线条较为复杂,需要对其分析的时候使用。

导出图片:若想把当前某一时间段图表分享给他人,或是生成可视化报表,拖动到合适的时间轴,点击导出即可生成图片以供下载。
按需加载

若线条过于繁多,影响分析,可点击上方按钮,隐藏部分曲线。
# 概念
# 应用指标
Java
内存、GC、线程、类加载器。NodeJS
内存、异步资源、Cluster • 总堆内存:指堆最高可用占用机器的内存。 • 常驻内存,指固定占用的内存。 • 异步资源-请求数:指使用异步请求的调用数量。HTTP请求
• HTTP URL:HTTP请求的全路径。
• 请求耗时平均值:指HTTP请求到响应一段时间范围内的聚合平均数。
• 请求次数:可以反映某个请求的调用情况。
• 机器IP:以机器IP做为分组,可结合查看不同机器的HTTP响应情况。RPC请求
• Dubbo Method:RPC请求的方法。
• Dubbo Service:RPC的服务类别。
• 请求耗时平均值:指Dubbo请求到响应一段时间范围内的聚合平均数。
• 请求次数:可以反映某个RPC方法请求的调用情况。
• 机器IP:以机器IP做为分组,可结合查看不同机器的RPC响应情况。数据库请求
• 数据库类型:可使用分组来显示不同数据库类别的状况。
• 请求耗时最大值:指数据库请求到执行完操作一段时间范围内的聚合最大数。
• 机器IP:以机器IP做为分组,可结合查看不同机器的数据库请求情况。缓存请求
• 数据库类型:可使用分组来显示不同缓存数据库类别的状况,如Redis。
• 请求耗时最大值:指缓存请求到执行完操作一段时间范围内的聚合最大数。
• 机器IP:以机器IP做为分组,可结合查看不同机器的缓存请求情况。消息队列请求
• Message Bus Destination:消息队列发送地址。 • Message Bus Status:消息队列发送状态。
# 图表类型
折线图/面积图
• 关注指标的变化趋势。柱状图
• 反映数值的差异,易解读。饼图
• 反映某个部分占整体的比重。漏斗图
• 适用于业务流程比较规范、周期长、环节多的流程分析,通过漏斗各环节业务数据的比较,能够直观地发现和说明问题所在。地图
• 关注指标的分布情况,如不同省份的响应延迟时间。表格
• 可用自定义表达式配置,满足更多复杂查询。![]()

# 聚合方式
不同的类型,有不同的聚合可以选择。
# 数值类型
- 平均值
- 最大值
- 最小值
- 总和
- 计数值
- 最新值
# 字符串类型
- 去重数量
- 计数值
- 最新值
什么样大的情况下选什么样的聚合方式,和数据本身的含义,以及想要展示的数据形式都有关系。
# 平均值
一般是数据时时刻刻在波动变化的,单看某一刻的数值意义并不是特别大,那么就可以使用平均值。
比如:
- CPU的使用率时时刻刻在变化,用平均值来显示,能够大概反映出某段时间机器的忙碌状况。
- 类似的指标还有 系统负载。
- 当然如果想了解这些指标的峰值情况,也可以选最大值。
# 最大值
如果数据本身是波动变化的,每一条数据都代表那一刻的状态,但更关注数据峰值情况,那么可以选最大值。
比如:
- 内存的使用情况,因为已使用内存超过限制就会导致容器OOM,所以可关注已使用内存的最大值。
- 有当前的在线人数的指标,也可以选最大值来反映某段时间里的最大同时在线人数的情况。
# 最小值
和最大值类似,但更关注数据的低谷值的情况,就可以选择最小值。
比如:
- 可以根据组件历史使用资源的最小值作为参考,来配置dice.yml的资源请求值。
- 如果数据中有一个时间字段,想查看最早的时间是什么时候,可以对时间字段求一个最小值。
- 结合最大值和最小值,求一个差值,比如 max(value) - min(value)。
# 总和
每一条数据代表一次或几次的统计值,需要累加起来才有意义的情况下,可以配置总和。
比如:
- 网关的请求,一条数据代表几次访问的统计,如果想查看某段时间内的总请求量,可以把这些零散的统计数据加起来,那么就可以选择总和。
- 页面的请求,一条数据代表几次访问的统计,需要查看页面的总访问量。
# 计数值
统计数据本身的条数,一条数据代表一次统计量,可以用这种聚合。 比如:
- 一条数据代表一次告警信息,那么用计数值来统计总数量。
- 一条数据代表一次用户的操作,也可以用计数值。
# 最新值
获取某段时间内,数据的最新值。 比如:
- 如果一个值是固定不变的,取任何时候的值都是一样的,那么可以选最新值,或者不选任何聚合方式,比如机器的CPU核数、总内存数。
- 如果一个值是变化的,但更关注最新的状态,也可以选最新值,比如在配置卡片图的时候,想看到某个机器最新的内存使用情况,就可以配置最新值。
# 去重复数
每条数据都有一个可能重复的ID,希望统计出不同ID的数量,那么可以用这种聚合方式。 比如:
- 每个容器都有多条数据,每个容器都有唯一的ID,可以统计不同容器ID的数量,即容器ID去重复后的数量,来代表容器的数据。
- 类似的,根据用户ID,统计不同用户ID的数量,代表用户数。
# 表达式
配置表达式是在表单配置无法满足的情况下,退而求其次的一种方式。
配置表达式意味着需要对数据的字段和类型有一定的了解。
这里也稍微介绍一下表达式的配置。 指标查询实现的是一种时序数据查询语言 influxql,是一种类SQL的语法,一个完整的表达式如下:
SELECT
[表达式 AS 别名, ...]
FROM 指标名
WHERE 过滤条件
GROUP BY [表达式, ...]
ORDER BY [表达式 DESC, ....]
LIMIT 限制数据量;
例如:
SELECT
field1::field,
tag1::tag, others AS alias
FROM metric_name // 指标名
WHERE
tag2::tag='xxx' AND field2::field>100
GROUP BY host_ip::tag
ORDER BY field3::tag DESC
LIMIT 100;
其中,除了 SELECT 和 FROM,其他部分都是可选的。
表达式支持基本的四则运算,支持一些内置的处理函数。
# 表达式配置

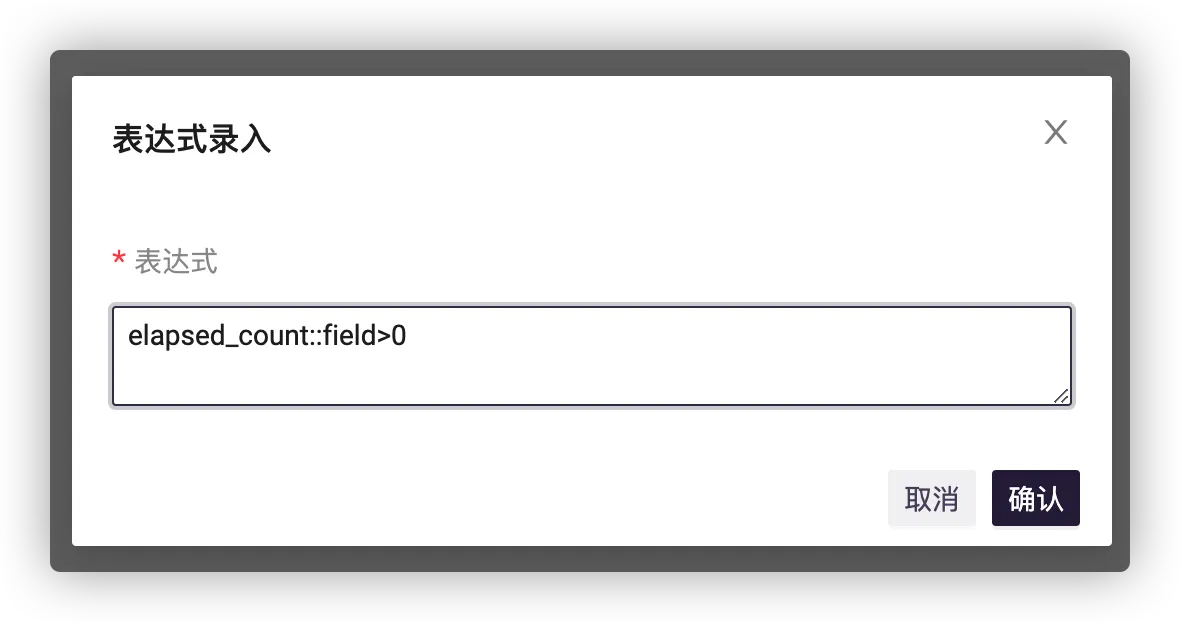
# 过滤表达式
字符串类型的字段支持:
- 等于,=
- 不等于,!=
- 正则表达式,=~
数值类型的字段支持:
- 大于,>
- 大于等于,>=
- 小于,<
- 小于等于,<=
几个需要过滤表达式的例子:
1、特别复杂的 AND OR 关系过滤条件组合,可以使用表达式,比如:
(tag1='value1' OR tag2='value2') AND (field1>=0 OR field2<100)。
2、多字段判断,比如 tag1=tag2+'subfix' AND field1<field2。
3、搭配一些常量函数,比如 field1 < max_int64() AND field2<now()。
# 查询字段自定义函数
在查询的字段中可以添加一些自定义函数,以便特殊情况下使用,如:
1.需要将不同的数值映射成不同的文字,map(field1::field,1,'result1',2,'result2'),这样field1:field为2的时候就会转化成result2。
(进阶)2. 需要确认是field1是否大于field2,是则显示result1,否则显示result2, if(gt(field1,field2),result1,result2),与三元表达式相同。
更多自定义函数可见《运维大盘进阶(指标查询语言)》 。