# 使用持续分析排查JAVA应用内存泄露的问题
# 背景说明
我们在一个 java 应用中构造了一个接口,调用该接口后会触发一个持续消耗内存的方法,进而导致该应用的整体响应时间偏高,该文章用于说明如何使用 Erda 来最终定位到是哪个方法消耗的内存。
# 使用 Erda 定位问题
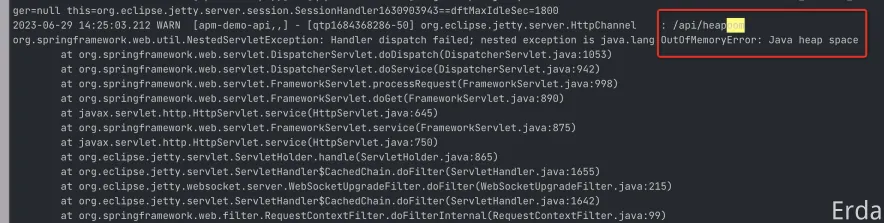
内存泄露,最直接的影响就是会导致 jvm 抛出 outofmemoryerror 的报错,如果你配置了容器 OOM 的告警,同时也会收到一条应用实例 OOM 的告警。

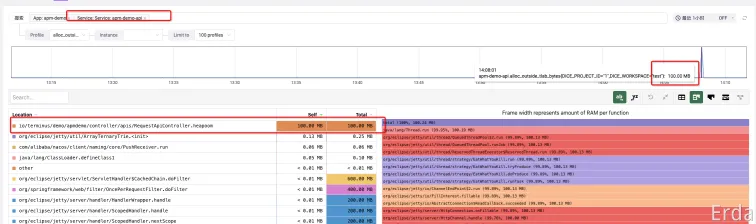
我们可以使用持续分析功能来定位具体是哪个方法消耗了比较多的内存,进入到微服务治理平台中,去搜索对应的应用服务,查看 alloc_outside_tlab_objects 类型的 profile 数据,可以比较清楚的看到消耗内存最多的是 heapoom 方法。
这里为什么需要查看 alloc_outside_tlab_objects 类型的 profile 数据呢,需要从 JVM 的内存分配机制说起,TLAB 的全称是 Thread Local Allocation Buffer,JVM 默认给每个线程开辟一个 buffer 区域,用来加速对象分配。这个 buffer 就放在 Eden 区中。对象的分配优先在 TLAB 上分配,但 TLAB 通常都很小,所以对象相对比较大的时候,会在 Eden 区的共享区域进行分配,对应的示意图如下。

最后我们贴一下最终有问题的 heapoom 法实现。可以看到方法中通过给 ArrayList 中每隔一秒添加 10MB 的数据,从而引起内存的 OOM。
public String heapoom() {
//List<Integer> list = new ArrayList<>();
int _10MB = 10 * 1024 * 1024;
List<byte[]> byteList = new ArrayList<>();
for (int i = 0; ; i++) {
byte[] bytes = new byte[_10MB];
byteList.add(bytes);
System.out.println(i + " * 10 MB");
try {
Thread.sleep(1000);
} catch (Exception e) {
}
}
}
# 总结
最后,我们可以总结出排查 JAVA 服务响应时间高的一般套路,可以借助 Erda 的微服务治理平台,总服务的黄金指标(R.E.D)一路往下分析,ERDA 提供了时间维度的指标跟 trace 的关联,以及 trace 中 span 发生时间点上的 pod 执行,机器指标,中间件指标,jvm 指标,日志的关联,最后也提供了代码级别的 profile 数据用于将问题原因锁定到具体的代码实现。
